
From Business Applications to AI: HSO’s Transformation Story
For many years, HSO has been recognised for its deep expertise in business applications and its ability to deliver complex, mission-critical solutions for customers across industries. That foundation remains central to who we are. However, the needs of our clients are evolving, as are we.
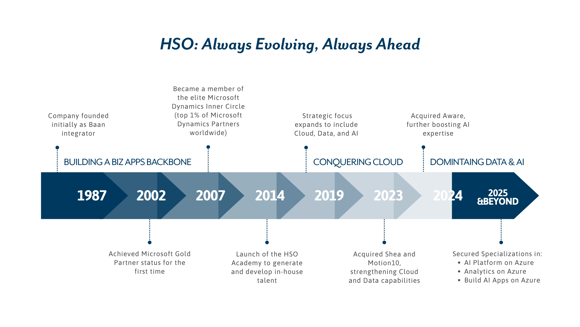
Building A Biz Apps Backbone
Since our founding in 1987, HSO has always been about staying ahead of what businesses need most. We began as an integrator of Baan software and quickly built a strong reputation as a trusted Business Applications specialist. Achieving Microsoft Gold Partner status in 2002 and joining the Microsoft Dynamics Inner Circle in 2007, placing us in the top 1% of partners worldwide, proved our commitment to excellence and innovation.
By helping organizations manage and integrate CRM and ERP processes through Microsoft Dynamics 365 Business Applications, we gave our clients a modern, flexible platform to connect systems, streamline operations, and make better decisions with real-time data and AI-driven insights. Strategic moves like acquiring Touchstone in 2010 and launching the HSO Academy in 2014 strengthened our people and expertise, ensuring we were ready to evolve as technology advanced, setting the stage for our next chapter.




Conquering Cloud
As the pace of digital transformation accelerated, HSO stepped forward again, building on our strong Business Applications foundation to guide organizations into the cloud era. Between 2015 and 2020, we broadened our capabilities to help customers shift from legacy, on-premise infrastructure to the scalable, secure power of the Microsoft Azure cloud.
We launched Managed Services in 2016 to deliver continuous optimization and peace of mind, and expanded into India, France, Switzerland, and the USA in 2018 to support clients worldwide. With a complete Azure services portfolio, covering strategy, architecture, infrastructure, security, integration, low-code development, and the modern workplace, we empowered businesses to modernize faster, reduce complexity, and unlock new levels of agility. By embracing what’s next, we proved once again that when technology moves forward, so does HSO.
Dominating Data & AI
Today, HSO’s evolution continues at the forefront of Data and AI. Building on our cloud expertise, we made bold moves, acquiring Shea and Motion10 in 2023 and Aware in 2024, to deepen our capabilities and help clients unlock even more value from their data. In February 2024, we achieved Microsoft Solutions Partner designation for Data & AI (Azure) alongside all five other designations, and quickly secured Specializations in AI Platform, Analytics, and Building AI Apps on Microsoft Azure.
Our award-winning performance, being named Microsoft’s Global Partner of the Year for Dynamics 365 Supply Chain Management and a finalist in categories like Data & AI, Government, and Financial Services, shows how we continue to adapt to what the future demands. From Baan software to Business Applications, from on-premise to cloud, and now to advanced Data and AI, our story is one of constant evolution. As technology changes, HSO is ready, helping our customers seize what’s next.


Change is constant, evolution is a choice.
At HSO, we choose to keep moving forward. By evolving our capabilities and investing in new technologies, we grow alongside our clients and our people, transforming change into opportunity and insight into impact.