

HSO AI Readiness Assessment
Start your AI journey with this proven approach to adoption

AI Proof of Concept (PoC): Guide for Businesses

Gartner predicts that through 2026, organizations will abandon 60% of AI projects - not because AI doesn't work, but because they weren't clear on what they were actually trying to prove.
The difference between AI initiatives that scale and those that quietly get shelved often comes down to how the proof of concept was designed from the start: the right scope, the right data, the right question.
This guide breaks down what an AI proof of concept is, how it differs from a prototype, pilot, or MVP, and what it takes to run one that gives you a real answer.
What Is an AI Proof of Concept (PoC)?
An AI proof of concept is a bounded, time-limited experiment designed to answer one question: can this AI approach work for this specific problem, in this specific context, with this data?
It is not a product. It is not a demo to present at a board meeting. It is a structured test of a hypothesis - designed to produce a decision.
The output of a well-run POC isn't a working application; it's a clear answer. Should we invest further in this approach, or redirect resources before committing serious budget? A well-scoped POC delivers that answer in four to eight weeks, at minimum cost and with maximum clarity.
A POC is not:
Each of those things is valuable in the right context. None of them is a POC.

AI POC vs Prototype vs MVP vs Pilot: What's the Difference?
These four terms are used interchangeably in most organizations. They shouldn't be - each stage answers a different question and carries a different level of investment and risk.
Confusing a POC with an MVP is a common causes of early AI project failure. Stakeholders expect a production-ready product; the team delivers a technical feasibility test. The result is frustration, misaligned expectations, and a project that gets cancelled for the wrong reasons.
| Stage | Primary Question | Audience | Data Environment | Typical Duration | Success Metric |
|---|---|---|---|---|---|
| Proof of Concept (POC) | Can this be done? | Internal technical reviewers, business sponsor | Sample or synthetic data | 4-8 weeks | Feasibility confirmed; Go/No-Go decision |
| Prototype | What will it look like? | Design teams, select users | Mock or limited read-only data | 2-4 weeks | UX usability and stakeholder understanding |
| MVP | Will people use it? | Early adopters, specific internal team | Production data (limited scope) | 3-6 months | Usage, retention, or revenue generation |
| Pilot | Will it break at scale? | A segment of real users | Live production data, full integration | 3-6 months | System stability and full rollout readiness |
The transition between these stages is where most AI projects fall apart. A POC might prove that an LLM can summarize a contract with 90% accuracy - but the subsequent MVP phase might reveal that the cost of running that query at scale makes the solution economically unviable.
What Makes AI POCs Different from Traditional Software POCs?
Traditional software POCs test whether something can be built. AI POCs test whether a probabilistic system can be trusted - and that's a harder question to answer.
In traditional software, a POC is largely a binary check: does System A communicate reliably with System B? The code either works or it doesn't. If it works in the test, it works in production.
AI systems don't work that way. They are probabilistic. The same prompt can produce different outputs on different days, with different phrasing, or against slightly different data. A AI model might perform well on your sample dataset and fail on real production data. It might be accurate 90% of the time - and wrong in ways that matter the other 10%.
This means AI POCs require a fundamentally different evaluation approach:
When developing AI agents or RAG applications, selecting the appropriate tooling is critical to balancing flexibility, cost, and operational complexity.
Why Run an AI POC? The Case for De-Risking AI
AI projects fail for four predictable reasons. A well-scoped proof of concept surfaces all four before you've committed serious resources.
Up to 70-80% of AI initiatives never reach production. They stall in what the industry calls "POC Purgatory" - technically functional in a sandbox, but unable to clear the bar for business viability, data quality, or organizational readiness. The POC is the mechanism that prevents you from discovering that bar at the wrong point in the investment cycle.
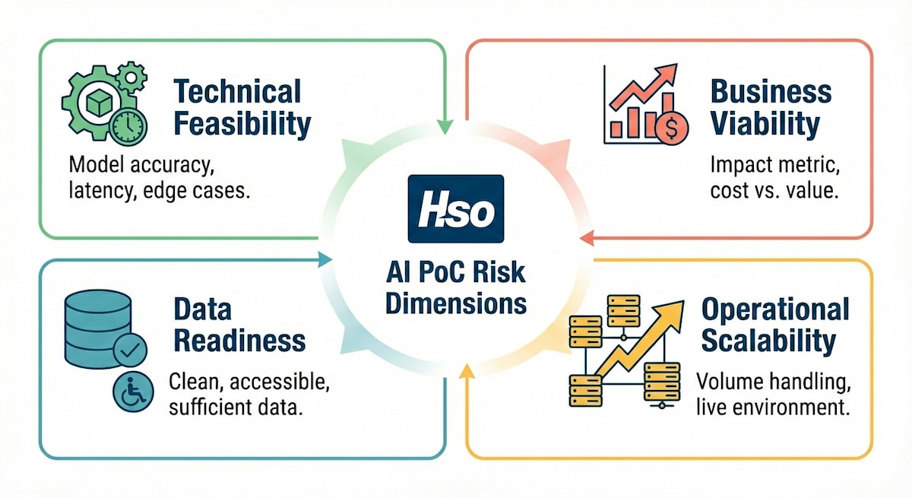
A well-designed AI POC tests four risks in parallel:
Miss any one of these, and the project fails - at a stage where the cost of failure is far higher than it would have been during a four-week POC.
How to Select the Right Use Case for an AI POC
The most technically impressive use case is rarely the right starting point. The right use case sits at the intersection of high business value and high data readiness.
A AI POC that tests a complex, multi-system agentic workflow against data that doesn't yet exist will teach you nothing useful. A POC that tests a focused hypothesis against clean, accessible data will give you a defensible Go/No-Go in four weeks.
Research from McKinsey indicates indicates that approximately 75% of the economic value of generative AI concentrates in four business functions, with an estimated annual value between $2.6 trillion and $4.4 trillion.
Prioritizing these areas maximizes the likelihood that a successful AI POC leads to meaningful ROI.

POC Starting Points HSO Recommends
HSO regularly recommends these use cases as high-value, high-feasibility starting points for enterprise AI POCs. In fact, HSO has ready-made AI agents built to solve some of these exact problems. Each has a tested hypothesis, known data requirements, and clear success criteria.
Running an AI POC: An 8-Step Playbook
A structured POC process turns an experiment into a defensible business decision.
The most common reason POCs produce no useful output is that they were never structured as an experiment. They started with enthusiasm and ended with "it kind of works." The following eight steps produce a decision, not a demo.
Start with a measurable KPI, not a feature wishlist. "We want to use AI for customer support" is not a testable hypothesis. "We want to test whether AI triage can handle 40% of incoming tickets with >90% accuracy" is. One of them produces a Go/No-Go signal. The other produces a prototype.
One use case. One dataset. One question. Every additional use case added at this stage doubles the complexity and halves the clarity of the output. If the first hypothesis proves positive, you'll have the foundation to run the next POC in half the time.
Data readiness is the most common POC killer. Before any build starts, audit your data: Can you access it? Is it clean enough to test against? Does it contain PII that needs to be handled before it enters the POC environment? Is there a sufficient volume to validate the hypothesis?
If the answer to any of these is unclear, the data assessment is your first deliverable - not the AI build.

HSO recommends matching tooling to the fidelity the POC requires - not defaulting to the most complex option available:
AI Security is not a final step. Define roles and access controls before the first resource is provisioned.
HSO's guidance is clear: request only the roles you need, enforce least-privilege access, and keep production data out of the sandbox unless it has been properly AI governed and anonymized. This is not just good practice - it is how you avoid a AI compliance incident mid-POC.
Set your thresholds before you see any results. What accuracy level constitutes a pass? What is the maximum acceptable latency for the use case? What cost-per-query makes the solution economically viable? What user satisfaction score would confirm adoption?
Defining these after seeing results is not evaluation - it's post-hoc justification.
Examples:
Treat the POC environment as ephemeral and codified. Using Bicep and Azure Verified Modules means the environment is reproducible: if the POC succeeds, you can rebuild and harden it for production without starting from scratch. An environment built by hand cannot be audited, replicated, or trusted at scale.
An AI model that hits 92% accuracy on a test set but doesn't reduce processing time or operating costs has not proved its value. Always map technical metrics to business outcomes: accuracy to first-contact resolution rate, latency to user adoption, cost-per-query to cost-per-transaction saved.
The stakeholders who fund the next phase will ask about the business number - not the score.
HSO AI Readiness Assessment
Start your AI journey with this proven approach to adoption
When AI POCs Fail - and Why
Most AI POC failures are not random. They follow predictable patterns, and two high-profile examples make those patterns impossible to ignore.
The failures that attract attention are rarely pure technical disasters. They are the result of applying the wrong process to a problem that required rigor: insufficient scoping, no real evaluation criteria, and operational conditions that were never properly tested.
McDonald's deployed IBM Watson-powered AI order-taking to more than 100 US locations. The system was removed in 2024 after a string of failures - including orders being misheard and incorrectly processed - became widely documented.
The technical limitations were entirely foreseeable. The system struggled with accents, competing background noise, and complex or modified orders. None of these conditions were adequately tested before rollout. A voice AI that performs acceptably in a quiet environment is a fundamentally different problem from one operating in a fast-food drive-thru with ambient noise, dialect variation, and real menu complexity.
The lesson: Operational conditions are not optional POC scope. If the use case involves real-world noise, edge cases, or complex input variation, those must be in the test - not discovered after rollout.
Klarna deployed an AI assistant that handled 2.3 million conversations - two-thirds of their total customer service volume - within its first month. The system performed the equivalent work of 700 full-time agents while customer satisfaction scores held steady.
The reason it worked is straightforward: Klarna chose a single, well-scoped use case with clean data from years of customer interactions, defined a clear success metric (resolution rate), and phased the rollout. They did not attempt to automate all of customer service at once. They proved one hypothesis and scaled from there.
The lesson: Narrow scope, clean data, and a clear success metric produce a POC that answers the question. The Klarna approach is not sophisticated - it's disciplined.
HSO Perspective: Building AI POCs That Actually Scale
HSO's approach to AI POCs starts with the business problem, not the technology, and uses the Microsoft AI stack to build reproducible, governed environments that are ready to scale if the POC succeeds.
The most expensive mistake in AI is building something impressive that can't be repeated, audited, or hardened for production. HSO structures POC engagements as if the environment might become a production system, because the ones that succeed will.
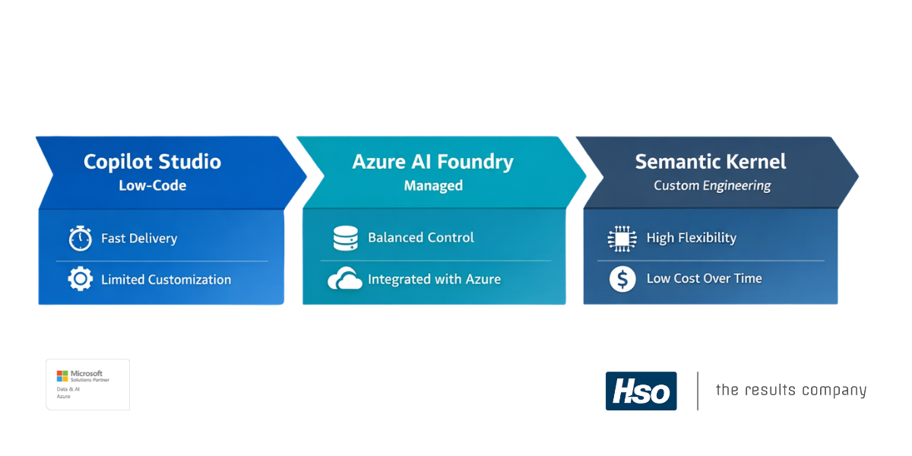
Choosing the right tooling is a strategic decision, not a default. HSO recommends matching the tooling tier to the level of fidelity and control the specific POC requires.
| Tooling Path | Best For | Trade-offs |
|---|---|---|
| Microsoft Copilot Studio (Low-code) | Knowledge worker, customer support, fast demonstrations | Fastest to proof; higher long-term operational cost; limited customization depth |
| Azure AI Foundry / Microsoft Fabric (Managed) | RAG pipelines, structured data use cases, Azure-integrated environments | Balanced flexibility and control; retains IP; integrates with existing Microsoft stack |
| Semantic Kernel / Custom Engineering | Novel agentic workflows, production-representative builds | Highest initial complexity; lowest long-term cost; requires engineering resource |
An HSO AI POC engagement produces four specific outputs:

